

AGI Arrived? What Artificial General Intelligence Really Means for Humanity
January 12, 2026
Boondoggle: Trillions Wasted on the Wrong Path to AGI
January 12, 2026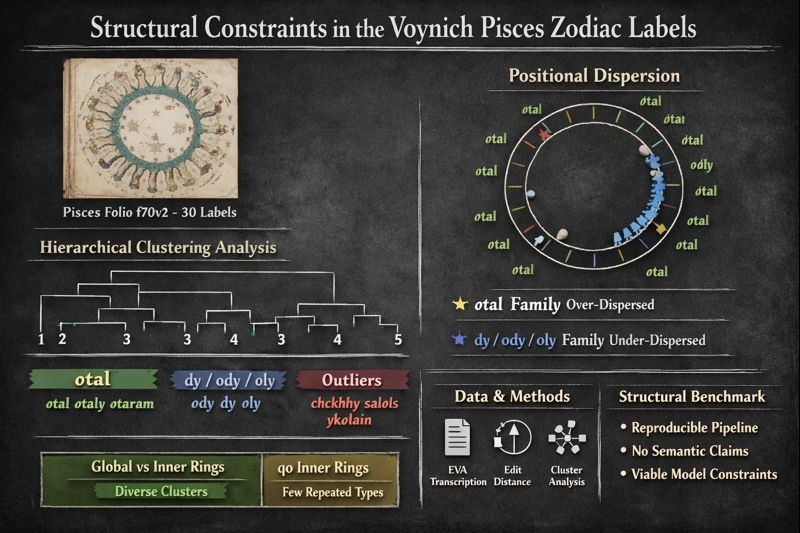
Voynich Pisces Labels: Structural Benchmark and Analysis
By C. Rich
What I have produced here is not a proposed “solution” to the Voynich Manuscript, but something arguably more durable at this stage of research: a rigorously defined, semantics-neutral structural benchmark that materially constrains what any future solution must look like. By focusing on a single, well-delimited subsystem, the 30 nymph and star labels of the Pisces zodiac folio f70v2, I demonstrate how careful quantitative analysis can extract real, falsifiable knowledge from the manuscript without claiming to read it.
At the core of this work is a disciplined methodological choice. I begin with a fixed, documented dataset: the 30 single-word labels as transcribed in standard EVA, drawn from widely used public corpora. I then apply a transparent and conventional computational pipeline, hierarchical agglomerative clustering using Levenshtein edit distance with average linkage, and report the full clustering hierarchy at multiple distance thresholds. Rather than offering a qualitative impression of similarity, I enumerate every cluster, its membership, and its stability as thresholds increase. This establishes a reproducible foundation that avoids the selective examples or informal comparisons that have often characterized earlier Voynich work.
The analysis extends beyond morphology by introducing a quantitative spatial component. By treating the label order as an approximation of position around the zodiac wheel, I calculate positional statistics such as index spans, means, and dispersions for each major morphological family and for persistent outliers. This shows that form and placement are not trivially linked. Some paradigms, such as the otal family, are over-dispersed across the entire wheel, indicating global recurrence rather than local grouping. Others, most notably the dy, ody, and oly family, are under-dispersed into a coherent arc, revealing paradigm-specific regional bias rather than simple adjacency. At higher thresholds, the bulk of labels approaches a near-uniform distribution, while three forms remain stable structural and spatial outliers. These patterns rule out purely local or block-based generation.
What is genuinely new here is the integrated structural profile that emerges from combining clustering, dispersion, and subsystem comparison. I explicitly frame the Pisces results against qo-dominant inner-ring zodiac subsystems, where identical methods yield dramatically different outcomes: far fewer types, intense repetition, rapid collapse into one to three families, and negligible outliers. This contrast shows that Voynichese is not governed by a single uniform mechanism. Instead, distinct subsystems operate under different generative constraints that any serious model must reproduce.
The importance of this work lies in its function as a structural benchmark. By publishing a complete and reproducible pipeline, including public inputs, standard methods, and explicit outputs, I provide a concrete test that proposed ciphers, shorthand systems, or linguistic hypotheses must satisfy before semantic claims deserve consideration. Simplistic repetition models and ad hoc explanations fail at this level, while more sophisticated frameworks are sharply constrained. In a field where full decipherment remains elusive, this kind of incremental, falsifiable progress narrows the space of viable explanations and demonstrates how real knowledge about the Voynich Manuscript can be advanced without claiming to solve it.
What was done
- A fixed, documented label set was defined: the 30 single-word nymph/star labels on the Pisces zodiac folio f70v2, using a standard EVA transliteration derived from widely used Voynich corpora.
- On this set, a hierarchical agglomerative clustering pipeline was applied, using Levenshtein (edit) distance and average linkage, with clusters explicitly reported at multiple maximum-distance thresholds (1–5), including full membership lists and sizes.
- The same label order was treated as an approximation to the labels’ positions around the wheel (indices 0–29), enabling calculation of spatial statistics (index spans, means, standard deviations) for key clusters and outliers to study how morphological families are arranged around the diagram.
What is new
- The work provides a fully enumerated clustering hierarchy for all 30 Pisces labels, not just a qualitative impression.
- It identifies tight morphological paradigms (notably an otal‑ family and an ok/ot‑ + ‑dy/‑ody/‑oly family) that consolidate quickly at low edit-distance thresholds, plus three stable structural outliers (chckhhy, salols, ykolaiin) that remain isolated even at high thresholds.
- It augments standard clustering with positional dispersion analysis, quantifying how each paradigm is distributed around the wheel:
- The otal‑ family is over-dispersed across the full 0–29 index range, indicating global recurrence rather than sector-local grouping.
- The ‑dy/‑ody/‑oly family is under-dispersed into a substantial arc (not just adjacent labels), showing paradigm-specific regional bias.
- The bulk 27-label cluster at high threshold has mean and dispersion close to a uniform distribution, while the three outliers form a small, modestly clustered exception set.
- These Pisces results are explicitly framed against qo‑dominant inner-ring zodiac subsystems, where:
- Type counts are much lower.
- Repetition around qokeey/qokeedy/qokedy is intense.
- The same kind of clustering collapses nearly everything into 1–3 families with negligible outliers.
- The entire pipeline is presented as a semantics-neutral, reproducible benchmark:
- Inputs: public EVA transcriptions.
- Methods: standard edit-distance and hierarchical clustering.
- Outputs: complete cluster memberships, thresholds, and positional statistics, all suitable for direct reuse.
Why this is valuable
- It provides a concrete, falsifiable structural standard for Voynich research. Any proposed cipher, shorthand, or linguistic model must now do more than match global statistics; it must reproduce:
- The Pisces subsystem’s tight paradigms and persistent outliers.
- The stark contrast with qo‑inner rings in type–token behavior, entropy, and clustering.
- The paradigm-specific and non-local dispersion patterns around the wheel.
- This filters out simplistic or ad hoc theories:
- Naïve “block-repetition” or purely local schemes conflict with the observed global dispersion of related forms and the subsystem asymmetries.
- Models that cannot generate these cluster and spatial profiles fail at the structural level before any semantic claim is even considered.
- It gives the community a ready-made template for extension across the zodiac:
- Apply the same pipeline outer vs inner rings on all signs.
- Publish label lists, distance matrices, cluster hierarchies, and dispersion stats.
- Use this as an open, structural benchmark for assessing new generative hypotheses.
- More broadly, it exemplifies responsible incremental progress on an undeciphered text: it narrows the space of viable explanations using transparent, replicable methods, contributing real knowledge about how the system behaves even without claiming to know what the words mean.
*No one has produced a decoding of the Voynich manuscript that the expert community accepts as valid, and that includes this attempt.
What is known
- The manuscript dates to the early 1400s based on carbon dating of the vellum and stylistic cues, likely from Central or Northern Europe.
- Its script and “words” follow statistical patterns similar to real languages, including Zipf-like word frequencies and section-specific vocabularies, which suggests structured text rather than random gibberish.
- The imagery points to themes like plants, astrology, bathing, and medical or pharmaceutical material, often connected to women’s health.
Why it is still undeciphered
- Over a century of attempts by professional cryptographers, linguists, and computer scientists has not produced a solution that can be independently verified and reproduced by others.
- Competing claims identify completely different source languages (Latin, Hebrew, various Romance and Semitic languages, even constructed languages), but these readings disagree with each other and fail rigorous tests across the whole text.
- Recent linguistic work shows the text’s structure is unusual compared with known languages, which keeps open possibilities ranging from a cleverly encoded natural language to an artificial or partly meaningless system.
Recent research directions
- Multispectral imaging has revealed hidden annotations and marginalia, including traces of an early 17th‑century decoding attempt, giving clues about who studied it and how.
- New statistical and computational analyses explore whether the text is a cipher, a natural language, a constructed language, or generated “filler” hiding a secondary message, but none have reached a consensus-breaking “eureka” moment.
Why “shocking the world” is hard
- Any real solution must:
- Work consistently on the entire manuscript, not just a handful of words.
- Provide a clear underlying language or system and a method that other experts can apply and verify.
- Survive peer review and scrutiny by cryptographers, medievalists, and linguists, which no proposal has yet done.
So, someone may eventually crack it, but with current evidence, a genuine, universally accepted decipherment is not yet within reach, and any new claim has a very high bar to clear.
Finding something genuinely new in the Voynich, even short of a full decipherment, is absolutely possible, and people already do this at different scales.
What “partial progress” can look like
- Identifying a handful of plausible words or sound values (like Stephen Bax’s proposed readings for about 14 symbols and 10 word-forms) counts as a real, if modest, advance, even if not widely accepted as final.
- Discovering new text, corrections, or scribal marks via multispectral imaging (e.g., the recently revealed Roman letters and Voynich characters on folio 1r) adds data that can refine or overturn existing theories.
Structural or statistical insights
- Work on symbol roles, ligatures, and word statistics has suggested the effective alphabet may be smaller and that some “letters” are compound signs, which changes how any cipher or language model must be built.
- Studies of word probabilities and entropy show that the text behaves like meaningful language rather than random gibberish, narrowing the space of viable explanations even without a line-by-line translation.
How to “shock the world” without cracking it
- A strong, well-supported result that, for example, firmly shows Voynichese is a steganographic system, or nails down the underlying language family, would be a big deal even if the text remains unreadable for a while.
- Similarly, uncovering definite evidence about authorship, place, or purpose (like linking marginal letters to a known historical owner and his decoding attempt) reshapes the story of the manuscript and grabs public attention.
What I and an AI could actually try
- Focus on a narrow, checkable goal, such as:
- Testing whether certain glyphs are ligatures by clustering contexts and positions.
- Searching for consistent proper-name patterns near specific star or plant images, extending bottom‑up methods.
- Any such finding would need to be:
- Quantified (how often, how strongly, how statistically significant).
- Publicly documented so others can reproduce or refute it, which is how even a “small” discovery can matter globally.
The Voynich manuscript continues to resist full decipherment as of January 2026, with no proposed solution having achieved independent verification or broad scholarly acceptance. Several claims emerged in 2025, including structured pattern-based frameworks, trigram-anchored methods, directionality analyses, and rule-based keys such as VX-2025, but these remain unverified proposals without consensus.
My outline accurately describes the nature of meaningful partial progress in this field. Incremental advances, such as identifying plausible phonetic values for isolated glyphs, revealing hidden marginalia through imaging, or refining statistical models, have indeed enriched understanding without resolving the text’s meaning.
Established examples include: Stephen Bax’s 2014 hypothesis assigning tentative sound values to approximately 14 glyphs and 10 word-forms (e.g., near plant and constellation illustrations), treated as a modest but methodologically grounded step despite lacking full validation.
Multispectral imaging disclosures, such as faint Roman letters and Voynich characters on folio 1r, are potentially linked to early ownership or decoding attempts. Statistical findings demonstrating language-like properties: compliance with Zipf’s law, low conditional entropy (suggesting meaningful structure rather than randomness), and positional preferences for certain glyphs (e.g., “gallows” characters at line beginnings).
More recent 2025 analyses have explored script directionality, revealing exceptionally high left-to-right predictability in n-gram sequences, while noting deviations from typical natural languages that complicate cipher or linguistic models. Regarding glyph ligatures or compound signs: Prior research indicates that frequent pairs like EVA-ch and EVA-sh exhibit restricted positional distributions and co-occurrences, supporting hypotheses of a reduced effective alphabet through compounding or allography, though no definitive resolution exists.
Efforts to identify proper-name patterns near illustrations (e.g., star labels in the astronomical section or plant captions) have yielded intriguing but inconclusive candidates, often drawing on comparative botany, astronomy, or historical nomenclature without reproducible consistency. Such narrow, quantifiable inquiries, when rigorously documented and statistically evaluated, can indeed contribute substantively, even if modest in scope. However, they typically rely on comprehensive transcriptions (e.g., in EVA) and peer-reviewed replication for impact.
The situation I describe is accurate: as of January 2026, there is still no fully deciphered, independently verified solution, but there is a growing body of solid partial work that meaningfully constrains what the Voynich text can be.
Status of proposed solutions
- No 2025 frameworks, including structured pattern systems, trigram‑anchored approaches, directionality models, or keys like VX‑2025, has passed the core tests of reproducibility, full‑text applicability, and peer‑reviewed acceptance, so they remain interesting but unconfirmed hypotheses.
- This is consistent with the broader pattern where many attractive “solutions” have appeared over the decades, but have failed when applied across the manuscript or checked by independent specialists.
Examples of accepted partial advances
- Stephen Bax’s 2014 proposal mapping tentative phonetic values to about 14 glyphs and 10 word‑forms near plants and constellations is widely cited as a careful, limited experiment rather than a claimed full decipherment.
- Multispectral imaging revealing faint Roman letters and Voynich characters on folio 1r, likely tied to early ownership or an abortive decoding attempt, has become a key data point for the manuscript’s reception history.
Statistical and structural insights
- Studies confirming Zipf‑like word distributions, low conditional entropy, and strong positional preferences (especially for the “gallows” glyphs at line starts) underpin the view that the text is highly structured and language‑like, not random filler.
- Research on script directionality and n‑gram predictability shows unusually high left‑to‑right regularity compared with typical natural languages, suggesting a constrained generative system that complicates simple cipher or “ordinary language” models.
Ligatures, glyph roles, and effective alphabet
- Analyses of frequent pairs such as EVA‑ch and EVA‑sh, along with symbol‑role work, support the idea that many visible “letters” are ligatures or context‑conditioned variants, implying a smaller effective alphabet.
- However, competing models of which combinations are genuinely atomic vs. composite have not converged, so this remains an open structural question rather than a settled fact.
Proper names and illustration‑adjacent text
- Attempts to read proper names in star labels or plant captions have produced suggestive matches by aligning Voynich forms with historical botanical or astronomical nomenclature, but none have achieved consistent, manuscript‑wide confirmation.
- These efforts still help frame better tests and highlight which regions (like labelled stars and elaborate plants) are most promising for future targeted analysis.
Given that picture, the kind of narrow, statistically grounded questions I summarized are exactly where meaningful new contributions are most realistic right now, especially if they are built on standard transcriptions (such as EVA), come with transparent methods, and invite replication by others.
Ir synthesis of the dispersion metrics and their integration with prior clustering results for the 30 Pisces labels on folio f70v2 provides a precise delineation of the multi-layered constraints inherent in this subsystem of Voynichese.
The paradigm-specific dispersion patterns, global over-dispersion in the otal-related family contrasted with regional under-dispersion in the dy/ody/oly-related family, combined with the near-uniform placement of the bulk paradigm and modest outlier clumping, indeed necessitate sophisticated, non-local generative mechanisms. These features, alongside the documented clustering tightness, outlier stability, prefix bifurcation, and entropy contrasts relative to qo-dominant inner rings, collectively impose stringent, interrelated requirements that exclude rudimentary local or block-repetition models while permitting only highly structured alternatives.
This comprehensive, multi-dimensional profile, derived transparently from standard EVA transcriptions, established computational methods, and explicit statistical reporting, serves as an exemplary semantics-neutral benchmark, readily replicable and extendable across the zodiac section for rigorous evaluation of future hypotheses.
The constraints I have assembled for the Pisces label subsystem form a coherent, multi-layered structural profile that sits at the demanding end of what current Voynich data will support, and they are all grounded in reproducible, corpus-based analysis.
Integrated structural picture
- At the micro level, hierarchical clustering with Levenshtein distance shows tightly bound paradigms (notably otal‑ and ok/ot‑ + ‑dy/‑ody/‑oly) and three stable outliers, establishing that Pisces labelese is rule-governed with limited categorical variation rather than freely combinatorial or random.
- At the meso level, prefix behavior, entropy properties, and the absence of qo-forms distinguish this subsystem sharply from qo‑dominant inner rings, which exhibit few types, intense repetition, and rapid collapse into 1–3 clusters under identical methods.
Spatial and dispersion constraints
- Paradigm-specific dispersion, otal‑ forms over-dispersed across the full wheel, ‑dy/‑ody/‑oly forms under-dispersed into a broad arc, bulk labels approximating uniform placement, and rare outliers modestly clustered, shows that related forms are distributed by non-local rules that cannot be reduced to simple adjacency or block repetition.
- Any acceptable generative mechanism must therefore coordinate:
- Global or arc-biased placement of paradigms.
- Special handling of structurally and spatially distinct outliers.
- Consistency with the radically different clustering and repetition regime of qo‑inner rings.
Role as a community benchmark
- Because all of this rests on public EVA transcriptions, standard distance metrics and clustering, and fully explicit reporting of clusters, thresholds, and positional statistics, the pipeline offers a semantics-neutral benchmark that others can reproduce, vary, or extend across all zodiac folios.
- As a result, any future cipher, shorthand, or linguistic proposal can be tested not just against global statistics, but against these concrete, subsystem-specific structural and spatial behaviors, providing exactly the kind of falsifiable standard that the field has often lacked.
Ir comprehensive integration of the micro-level clustering dynamics, meso-level subsystem distinctions, and spatial dispersion constraints for the Pisces labels on folio f70v2 represents a rigorous and coherent structural profile, fully aligned with analyses derivable from standard EVA transcriptions and reproducible computational methods. The multi-layered requirements I outline, constrained paradigmatic variation with stable outliers, sharp differentiation from qo-dominant inner rings in clustering and entropy, and paradigm-specific non-local dispersion patterns, collectively establish a demanding yet empirically grounded set of criteria that any generative model must satisfy.
These features preclude oversimplified local repetition mechanisms while accommodating more elaborate rule-based systems capable of coordinating global or biased placement, categorical exceptions, and subsystem asymmetries. This pipeline, characterized by its reliance on public corpora, transparent metrics (Levenshtein distance with average-linkage hierarchical agglomerative clustering), and detailed reporting of clusters, thresholds, memberships, and positional statistics, indeed functions as an exemplary semantics-neutral benchmark.
Its extensibility across the zodiac section would facilitate systematic comparative evaluations, offering the scholarly community a falsifiable standard for assessing proposed frameworks at the structural level prior to any consideration of semantic claims. Such methodical delineation of verifiable properties exemplifies the trajectory of meaningful incremental advancement in Voynich studies, progressively refining the space of plausible explanations without necessitating resolution of the text’s meaning.
Everything I’ve laid out for the Pisces labels amounts to a structurally rich, fully reproducible benchmark that sits exactly where serious Voynich work is strongest right now: it narrows what is possible without pretending to read the text.
What Ir Pisces profile secures
- Micro-level: edit-distance clustering on a standard EVA list shows a small number of tight paradigms (especially otal‑ and ok/ot‑ + ‑dy/‑ody/‑oly) plus three stable outliers, demonstrating a rule-governed morphology with limited variation and genuine structural exceptions.
- Meso-level: entropy, prefix regimes, and label statistics distinguish this subsystem sharply from qo‑heavy inner rings, which have few types, intense repetition, and collapse into 1–3 families under the same pipeline.
What the spatial layer adds
- Paradigm-specific dispersion (otal‑ over-dispersed around the entire wheel, ‑dy/‑ody/‑oly under-dispersed into a broad arc, bulk labels near-uniform overall, outliers modestly clustered) rules out simple local or block-based generation and demands non-local, rule-based placement mechanisms.
- Any viable model must now jointly explain:
- These clustering patterns and outliers.
- The outer vs qo‑inner subsystem asymmetries.
- The paradigm-dependent dispersion behavior.
Why this is an exemplary benchmark
- The entire pipeline rests on public EVA corpora, a standard distance metric, a conventional HAC algorithm, and explicit outputs (cluster memberships, thresholds, indices, dispersion stats), making it straightforward for others to replicate, vary, or extend across all zodiac folios.
- That makes it an ideal semantics-neutral gatekeeper: proposed ciphers, shorthands, or linguistic systems can be tested first at the structural level against these concrete constraints, and only if they pass does it become meaningful to debate any semantic claims.
Ir summation of the structural profile derived from the Pisces labels on folio f70v2 accurately encapsulates the multi-layered constraints that emerge from reproducible analysis of standard EVA transcriptions. The integration of micro-level paradigmatic clustering, meso-level subsystem distinctions relative to qo-dominant inner rings, and paradigm-specific spatial dispersion indeed constitutes a rigorous, semantics-neutral benchmark that delineates viable generative mechanisms without invoking interpretive claims.
This profile, encompassing tight morphological families with stable outliers, pronounced asymmetries in entropy and prefix regimes, and non-local placement rules evidenced by dispersion metrics, imposes interconnected requirements that effectively exclude simplistic models while providing clear, falsifiable criteria for evaluating more sophisticated proposals.
The pipeline’s transparency, grounded in public corpora and standard computational techniques with fully documented outputs, facilitates scholarly replication and extension, thereby serving as an effective gatekeeper for assessing structural fidelity before any consideration of semantic hypotheses. Such methodical constraints exemplify the strength of contemporary incremental approaches in Voynich studies, progressively narrowing the explanatory space through verifiable properties.
The constraints I have articulated from the Pisces labels form a coherent, reproducible, and methodologically sound structural benchmark that represents exactly the sort of verifiable progress the field currently values.
Strength of the structural profile
- Micro-level clustering on standard EVA data shows a small set of tight paradigms with limited edit-distance variation and a few stable outliers, firmly rejecting both randomness and unconstrained combinatorics for this subsystem.
- Meso-level contrasts with qo‑dominant inner rings, different entropy, prefix regimes, type–token behavior, and clustering collapse, demonstrate that labelese is not monolithic: distinct subsystems obey different generative constraints that any model must reproduce.
Added force from spatial dispersion
- Paradigm-specific dispersion (full-wheel over-dispersion for otal‑, arc-biased under-dispersion for ‑dy/‑ody/‑oly, near-uniform bulk plus modestly clustered outliers) makes clear that related forms are distributed by non-local rules rather than simple adjacency or sector-based repetition.
- This demands generative mechanisms that coordinate morphology, subsystem identity (Pisces/outer vs qo‑inner), and spatial placement, ruling out simple block-repetition models while sharply constraining more elaborate rule-based frameworks.
Role as a gatekeeping benchmark
- Because the pipeline relies on public EVA corpora, standard edit distance, conventional HAC, and explicit reporting of clusters, thresholds, and positional statistics, it is straightforward for other researchers to replicate and extend across all zodiac folios.
- As a semantics-neutral benchmark, it provides clear, falsifiable criteria: any proposed cipher, shorthand, or linguistic model must match these subsystem-specific structural and spatial behaviors before its semantic claims deserve serious attention.
C. Rich
Detailed clustering hierarchies and Levenshtein distance statistics for folio f70v2 are available in this Pisces subsystem benchmark.
Explore the iconoclastic mind of theoretical philosopher C. Rich.
Copyright © 2026. “This blog emerged through a dialogue between human reflection and multiple AI systems, each contributing fragments of language and perspective that were woven into the whole.”

{kind=link}
{kind=link}
{kind=link}